Executive Summary
In his confirmation hearing for the Secretary of Health and Human Services post, Robert F. Kennedy Jr. suggested directing at least 20% of the National Institutes of Health’s (NIH) budget toward replication studies — independent second-run tests of published results. That 20% would be almost $10 billion, roughly 2-3 orders of magnitude more than the total funding allocated to biomedical replication studies in the past decade.1 Such a reallocation would also divert a sum greater than the National Science Foundation’s total budget away from funding new biomedical research. Supporting replication is vital to advancing scientific credibility and progress, but resources for science are limited. How much should we actually spend on replication, and how do we ensure that amount is well spent?
We can answer these questions by quantifying a replication study’s return on investment (ROI) and identifying when it can outperform funding for new research. Our analysis suggests that, when targeted at recent, influential studies, replication can provide large returns, sometimes paying for itself many times over. Under plausible assumptions, a well-calibrated program could productively spend about 1.4% of the NIH’s annual budget before hitting negative returns relative to funding new science. But implementation matters: a poorly designed program or mistargeted grants can easily waste resources that might have otherwise generated new biomedical innovation or sped up the discovery of life-saving cures.
The case for replication
Science advances when researchers, labs, and disciplines build on one another’s ideas, gradually remixing and extending our knowledge in hopes of achieving a breakthrough. Because funders want to maximize the progress made with constrained budgets, resources have historically almost all been spent on growing new branches of science, funding research that expands on what’s been done rather than verifying existing studies.2
But we are now in a moment where the exponential growth of scientific output is slowing progress, frontier research is increasingly expensive, and norms like preprinting and data sharing make early evaluation more feasible. On the current margin, a dollar can sometimes go further by pruning existing branches to ensure that new research is built on strong foundations. Replication studies are one of the most efficient ways to do this pruning.
What counts as a replication?
Conceptually, replication aims to assess whether a study’s results accurately capture the underlying scientific dynamics being investigated; in practice, we try to answer this question by testing whether a study will produce the same (or similar) results when conducted a second time using the same (or similar) methods. But even this narrower definition encompasses a range of approaches.
Replication can refer to rerunning the original code on the original data to verify an answer; applying alternative analyses or assumptions to the original data to determine whether the answer is consistent;3 or re-doing an entire study, from data collection to analysis, using the methods described in the original. While the specifics can vary, the core goal of a replication study is to assess the rigor and validity of a previously reported finding. In that sense, follow-on studies that change key procedures and sample characteristics — or studies that use different methods to probe the same high-level idea — are best thought of as extensions rather than replications.
The following analysis is applicable across various types of replication but centers on full re-runs, particularly with respect to cost. That focus reflects the breadth of the NIH portfolio, which includes computational studies for which verification can be done cheaply and efficiently, but also spans many laboratory and clinical fields for which computational replication may be less applicable.
Put simply, a replication study provides scientific and social value by updating our understanding of an original study’s findings to be closer to the underlying truth. If the replication study finds results similar to the original, it increases our confidence in the original finding and derisks its use in future research, policy, and practice. If a replication study decisively fails to reproduce key results, it casts doubt on the original finding, preventing the spread and use of unreliable information.
In our current scientific ecosystem, explicit replications are rarely conducted, and most researchers do not wait for a successful replication before building or acting on a study.4 As a result, most of the value of a replication study lies in the possibility of overturning a finding.
Correcting the record may seem like an academic exercise, but it can mitigate substantial harm. Take the recent controversy in Alzheimer’s research, in which a series of fraudulent studies likely led to millions of dollars and years of effort pursuing a spurious lead. Or the fraudulent DECREASE trials, which made a harmful pre-surgery protocol look beneficial, influencing medical guidelines and potentially leading to tens of thousands of patients’ deaths. Replication studies are not the only way to detect flawed research, but they are a powerful tool for focusing attention and pursuing external validation. By shutting down false leads early, replications can prevent follow-on resources and research effort from being spent on fruitless quests that delay discoveries and cures, ensuring that unreliable research doesn’t get implemented into policy and practice.
It is worth noting that many important studies will be organically replicated over time as other labs try to build on them. Unfortunately, failures within these implicit replications can go unreported for years, since researchers — especially students and those early in their careers — who fail to recreate a result from a highly cited study will often assume they’ve made an error and move on without publicizing their results. This cycle then repeats across labs, wasting precious resources and effort. Making replication an explicit goal can speed up the process of detection and dissemination.
There is also hope that AI can help by automating replication, but near-term approaches will be limited to computational studies with shared data and, ideally, shared code. In biomedical research, this is still a relatively small (but growing) share of the research that warrants replication. Broad-based replication still requires considerable investment and dedicated effort.
Estimating the value of a biomedical replication
The case for funding replications is simple: they are often highly informative, can productively shape the direction of future research, and typically cost much less than a new study.5 Because replication studies are retrospective, the best opportunities can be more easily targeted; it is comparatively straightforward to identify the most consequential replication studies to fund, relative to appraising potential new research directions. But given finite resources, we need to evaluate not just whether funding a replication is a good investment, but when it is a better investment than funding new studies.
Four key factors can help us estimate the returns to funding a replication:
- The probability that a given study’s findings would be overturned by a replication
- The amount of downstream attention the study would receive in the absence of a replication
- The proportion of that downstream attention that would be preempted by a failed replication
- The cost of a replication, relative to the cost of the average new study
Likelihood of overturning a finding
A growing body of research aims to estimate replication rates across fields, with recent papers in psychology, biology, and economics suggesting that around 50% of studies don’t replicate. However, these estimates span the different definitions of “replicate” discussed above: from re-analysis of code and data, to new analysis and robustness checks, to the comprehensive replication of lab experiments using new data. There is also reason to believe that these are inflated estimates: sampling variability, methodological uncertainty, experimental skill, and even flawed power calculations can produce divergent results in a meaningful fraction of follow-up studies, for benign reasons. As a result, the probability of overturning a study’s core claims is likely substantially lower than the reported rates of unsuccessful replications.
A collection of 110 replication reports from the Institute for Replication offers a better estimate of the extent to which unsuccessful replication reflects genuine unreliability. Across these reports, computational reproduction and robustness checks fully overturned a paper’s conclusions around 3.5% of the time and substantially weakened them another 16.5% of the time.6 Computational reproducibility and robustness may not always reflect full replicability of the results, so the true rate of unreliable research might be higher. Counting all fully overturned cases and half of the weakened cases yields an estimated (and potentially conservative) ~11% rate of genuine unreliability across the literature.7
Downstream attention
A key parameter to consider when targeting replications is the amount of downstream attention a study would receive in the absence of a replication. Over its first 15 years, the median paper in medicine or biology receives ~50 citations. This is useful for assessing the potential value of broad-based replications, but the focus of a replication funding program should instead be on papers that would receive outsized attention. Papers in the 75th percentile accumulate closer to 150 citations in the first 15 years post-publication; in the 95th percentile, roughly 600; and in the 99th, over 1,300.
Conditioned on the attention that a study is likely to receive, the amount of downstream attention that would be preempted by a failed replication is subject to three important considerations:
First is when the replication happens — the attention a paper receives, and the extent to which it drives follow-on research, are time-dependent. Papers tend to accrue ~2.5% of their total citations in the first year after publication, 7.5% in the second, and ~12% each in years 3-5; by the sixth year post-publication, the average paper has already received almost half of the direct attention it ever will. Because the capacity of a failed replication to reduce a study’s impact depends on when the replication occurs, we should not prioritize replicating studies that have already accrued a lot of citations — at that point, it may be too late to capture most of the replication’s value. Instead, we should aim to replicate papers that are likely to accrue many citations in the future.
Beyond timing, we need to consider the extent to which a failed replication would actually affect other researchers’ follow-on behavior. The impact of retractions (when journals or authors withdraw papers) may be a useful benchmark — retractions reduce citations by ~60% almost immediately, and by 80% or more within a few years. Failed replications are unlikely to follow as dramatic a curve, but can still deter attention if the replication is rigorous and well-publicized.8 The literature on the citation impact of replications is mixed, but evidence suggests a modest effect: data from a recent paper, as well as analysis of a separate sample of replication studies, both show a ~10% reduction in citations in the first year after a failed replication, stabilizing at a ~35% reduction after a few years. We’ll use those figures to model the impact of a rigorous replication overturning a paper’s key results.
Many citations are ornamental; in these cases, averting a citation to a flawed study might shorten the citing paper’s reference list by one, but would not alter the study’s core goals, hypotheses, or methods. To understand the tangible benefits of replication, we should consider how many of those averted citations would have meaningfully influenced the direction of downstream research. One study surveyed researchers on how much their references affected their own studies and found that this influence is itself a function of the cited paper’s impact. For a study with 50 citations, approximately 7.5% of those citations reflect the study having had a “major influence” on the citing paper, which the study defines as “influenc[ing] a core part of the paper,” and another 2% reflect a “very major influence,” which is defined as having “motivated the entire project.” For a study with 2,000 citations, these rates are 12% and 3%, respectively.9 Based on those definitions, we can assume that removing a “very major influence” changes the direction of a study by 85%, and removing a “major influence” changes it by 25%.
Cost
To decide whether to fund replications or new biomedical studies, we need to consider the relative costs of each. A typical R01 — the NIH’s flagship grant mechanism — runs for four years at about $600,000 per year, totaling approximately $2.4 million. Each grant produces roughly eight papers, on average, yielding a per-paper cost of around $300,000.10
The cost of a replication varies depending on the nature of the study being replicated, but the best estimate comes from the Reproducibility Project: Cancer Biology — an effort led by the Center for Open Science to systematically replicate a set of preclinical research papers in cancer biology. They report an average replication cost of $52,574 per paper, not accounting for some administrative costs and donated reagents and supplies. This suggests roughly $75,000 as an expected all-in cost, or 25% of the cost of an original paper.
In summary, we can calculate the ROI of a given replication study as a function of dollars saved by avoiding wasted research effort relative to the cost of the replication study itself.11 Since the money saved can instead be invested into more promising research, we can think of this ROI as the relative impact of funding a given replication study compared to directing those funds toward new science.
When is a replication worth the cost?
Using the metrics discussed, we can derive that the expected ROI of funding a replication of a middle-of-the-road biomedical paper — one that is expected to amass 50 citations over 15 years, has a baseline 11% chance of failing to replicate, and was published three years ago — is 0.16, meaning that funding such a replication would be 84% less effective than using that money for new research.
But the manner in which replication funding is targeted can dramatically alter the returns that it provides to science and society. In this dashboard, you can tune the parameters discussed above to see the effect they can have on the ROI of replication vs. primary research. Below, we consider two additional scenarios of interest.
If we instead target a paper that is likely to be influential and seems slightly less credible than average — say, an expected 15-year citation count of 200, reflecting the ~80th percentile for biology or medicine, and an estimated 20% chance of failing to replicate — we get an ROI of 1.36, meaning that funding this replication is roughly 36% more impactful than using that money for primary research.
How about if we focus on a highly consequential study that the relevant discipline is somewhat skeptical of? In this case, targeting a study that is expected to amass 600 citations (~95th percentile) and has a one-in-three chance of being unreliable would yield an expected ROI of 7.77. This replication would be almost 8x as effective as using that money for traditional grants.
In each of these scenarios, the time since publication has been fixed at three years and the cost of replication fixed at 25% ($75,000). Importantly, these characteristics can also be targeted to great effect — in the last scenario, replicating a slightly newer paper (two years post-publication) and funding a lab that can perform the replication slightly more efficiently (at 20% of the original cost) boosts the ROI to over 11x.
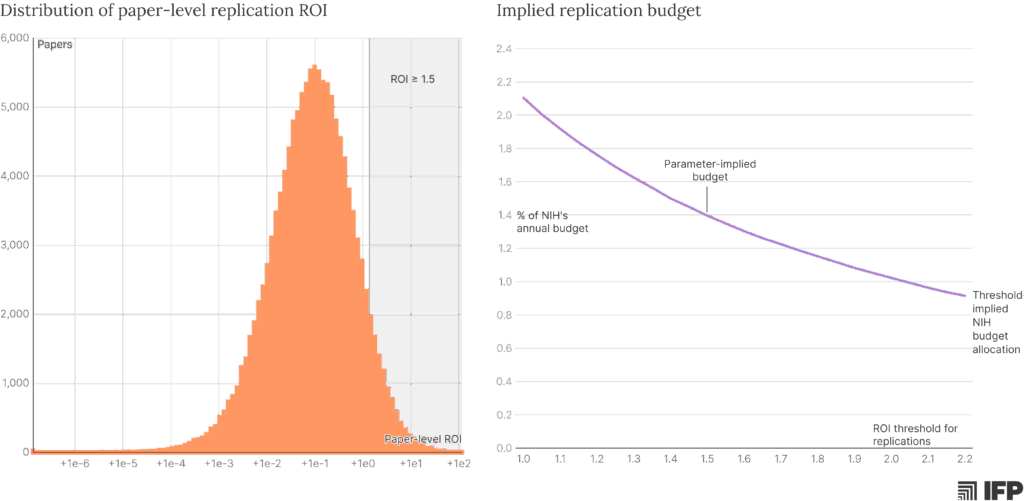
These estimates have implications not only for how we target an individual replication study, but also for how much funding can be productively allocated to replication at a program level. Using the parameters above and simulating paper-level citation potential and reliability, we can estimate that 5-10% of NIH-funded papers would have positive returns from replication (~10% with an ROI > 1.0, ~7% with an ROI > 1.5, and ~5% with an ROI > 2.0).12 Taking an ROI of 1.5 as a reasonable threshold for targeting high-value opportunities, and assuming an annual research expenditure of $39 billion13 and a cost-per-paper of $300,000, this suggests that replications would be valuable for roughly 9,000 of the 130,000 annual NIH-funded papers. At an average cost of $75,000 per replication, replicating these high-value papers would cost $675 million each year, or roughly 1.4% of the NIH’s total annual budget.
Designing an optimal replication funding program
Based on the characteristics of high-yield replication studies, an effective funding strategy needs to consider:
- Influence: The selection mechanism should prioritize replications of relatively new studies that are either already making a significant impact or seem poised to meaningfully inform the direction of future research. Citations are one way to assess potential influence, but they are a more useful metric in conjunction with the age of the paper and the manner of citation (i.e. are researchers citing a paper in a long list of related work, or are they actually trying to build on its core findings?). And when feasible to obtain, scientists’ assessments of which findings are likely to influence future research can be an even more accurate measure of potential significance.
- Uncertainty: Funding decisions should take into consideration signals from within the scientific community to identify which findings may not rest on a solid foundation; this knowledge is often held by grad students and post-docs working to build on new results, or shared within whisper networks of principal investigators. Eliciting this information and using it to identify candidate studies could dramatically increase the value of a replication program.
- Cost: A well-designed replication effort should have streamlined costs relative to the original study. This is not strictly necessary for influential studies — even a replication that is as expensive as the original could be positive ROI for a high-impact study with some signal of uncertainty — but all else equal, we should prioritize more cost-effective replications by identifying labs that have the right personnel, hardware, and resources to efficiently replicate a given study within their existing workflows.
- Speed: In the second targeting scenario above, the difference between replicating the study three years post-publication and six years post-publication is the difference between a positive ROI (+36%) and a negative one (-29%). A typical grant process, which can take one to two years from ideation to disbursement of funds, would mean that, at best, replications are published two to three years after the original study, even if selected immediately. We can capture significantly more value by creating a more agile process to source high-impact, high-uncertainty studies from scientists and get money out the door quickly.
How do various proposals for replication funding mechanisms stack up on these measures?
The NIH’s current replication funding mechanism is not well-designed to identify worthwhile replication opportunities. It sources ideas from the researchers who conducted the original study, which is arguably anti-correlated with both influence and uncertainty.14 The allowable cost is capped at $50,000, which is a reasonable figure but unnecessarily limiting. Notably, the agency recently launched the Replication Prize program, which seeks suggestions for both high-impact research in need of replication and strategies for integrating replication into ongoing work. Though this program only covers the idea-generation stage, these goals suggest a greater focus on targeting impact, uncertainty, and efficiency in future replication funding efforts at NIH.
A traditional grant mechanism, in which researchers submit proposals to replicate studies within their domain, could work under certain conditions. Ideally, researchers would be incentivized to replicate consequential studies with high uncertainty. However, in a bid to secure funding, they may instead pursue replicating convenient studies that they were planning to build upon anyway. For a traditional grant model to produce strong returns, the review process would need to be designed for effective prioritization. Additionally, the speed of a traditional review process — which can take 8-20 months from application to award — would be suboptimal unless implemented using a rapid funding scheme.
A regranting mechanism, in which the agency delegates a budget to a trusted third-party to solicit and fund replication studies, may speed up the process by allowing nimbler organizations to identify high-return replications and disburse funds. However, identifying the appropriate hosts would be critical. Assessing impact and uncertainty (especially for very new papers) requires deep domain knowledge of the field in which a replication study is being proposed. Since it would be difficult for any individual organization to source expert reviews across all of the fields covered by the NIH, this approach may require that the NIH provide regranting funds to several organizations across domains.
A bounty or market mechanism in which NIH grantees or other domain experts actively participate in prioritizing replications could be an alternative or a complement to the funding schemes above. In this approach, scientists would collectively allocate votes — or perhaps monetary bounties, drawn from a dedicated pot of NIH funding — to specific studies they would like to see replicated. This model could create an efficient information-gathering system, allowing the researchers best positioned to identify influential but questionable findings to signal their concerns directly. Labs capable of efficiently conducting these replications could then compete for bounties to optimize on cost. Alternatively, agency staff or a regranting organization could identify and fund labs directly through contracts or other transaction mechanisms to conduct the highest-impact replications quickly.
Alternative strategies proposed include a residency program to boost agency capacity for replications, the expansion of rigor-focused offices and using non-grant funding mechanisms, and leveraging the NIH’s Intramural Research Program to create a standing replication incubator. Though not primarily focused on external funding, each of these proposals has merit and should be considered as a component or complement to a considered replication strategy.
An effective funding program should pair a field-signaling strategy (bounties, markets, or embedded regranting organizations) with a rapid funding mechanism (a fast-grants scheme or more flexible non-grant authorities) to provide the best combination of targeting and efficiency. If designed well, the program will identify influential, recent studies with tangible stakes; fund and deliver independent re-runs quickly; and get information into the hands of researchers.
Replication is a tool for steering effort, not a rival to new discovery. A careless replication program risks diverting resources from important questions; a thoughtful one will shore up the foundations of biomedical science and accelerate progress along the field’s most promising paths.
-
In the past decade or so, there have been only a few large-scale funding programs related to reproducibility, totaling a few million dollars. Estimates suggest that there are 20-40 replication studies per year in the biomedical and health sciences. At a rate of $75,000 per replication, as discussed in the “Cost” section below, that amounts to ~$20 million over 10 years.
-
Studies across economics, psychology, and health sciences have found that only 0.1% to 0.5% of published research papers are replications. These figures reflect studies that either self-described as replications or had the explicit goal of reproducing prior research. A much higher proportion of studies investigate established ideas or previously published findings, but those studies typically aim to extend existing knowledge rather than validate it.
-
In some contexts, approaches that re-analyze original data are referred to as assessing “computational reproducibility” rather than “replicability.” In others, including in this piece, reproducibility and replicability can be used interchangeably.
-
Scientific institutions and researchers tend to have a strong preference for new discoveries over the correction of past studies or confirmation of their reliability. In general, this is an effective mechanism for incentivizing boundary-pushing research. But these norms also mean that replication studies are undersupplied, since researchers generally receive neither financial nor professional support to conduct, write, and publish replications, even if they are willing to do so of their own accord.
-
The cost difference is especially pronounced for computational replications, but it can also be meaningful when re-running a study, since the design and methods are already specified. This allows replicators to skip most of the ideation, iteration, and protocol development that can drive up first-run costs.
-
These figures are based on an assessment conducted by IFP Non-Resident Senior Fellow Matt Clancy.
-
Forthcoming research by Erik van Zwet, Andrew Gelman, and Witold Więcek suggests that the expected rate of sign reversals in empirical research — a scenario in which a follow-up study finds an effect in the opposite direction of the original — is between 10 and 20% across a broad set of topics, including in biomedical research. Compared to the higher rates of non-significant replication, such reversals are more likely to reflect the true unreliability of an original finding.
-
Even if a failed replication is decisive, its impact is likely to be lower than that of a retraction, for two reasons. The first is that, as discussed earlier, failed replications do not cast as much doubt on an original study’s findings as a retraction, making researchers less likely to change their behavior. The second is that retractions are highlighted on the webpage of the original study, and often within citation management tools, while replication studies are rarely linked to directly from original studies and therefore harder to find.
-
The cited study finds some heterogeneity across relevant fields. More specifically, life sciences citations tend to be more influential than average, while health sciences citations tend to be less influential. This analysis uses the overall average values.
-
A paper is a common and straightforward unit for which a replication effort would be conducted. One could instead replicate an experiment, a finding, or a grant, with costs and implications scaling based on the size of the effort relative to the average paper.
-
ROI ≈ (P[study overturned] × averted downstream effort × cost per paper) ÷ replication cost, where “averted downstream effort” is a function of the timing of the replication, the citations the original paper would have received, and the number of studies that would have been built off of it.
-
Specifically, this simulation models the citation distribution as a log-normal distribution with 𝜇=4 and σ=1.4, which produces roughly the same distributional features as the citation results discussed above; it models the paper-level probability of unreliability as a beta distribution with ɑ=1 and β=8, which produces a right-skewed distribution with an average value 0.11; and it assumes replications are published four years after the original paper and cost 25% of an average new paper.
-
Approximately 82% of the NIH’s $48 billion budget is spent on research grants.
-
Because a successful replication provides few benefits to a researcher, and a failed replication can undermine the original study, researchers are unlikely to proactively request that their most influential research be replicated. Naturally, they are even less likely to commission replications for their least reliable studies.



