This essay is part of The Launch Sequence, a collection of concrete, ambitious ideas to prepare the world for advanced AI. These projects need people to build them. Get in touch.
Today, with seed funding from Radial at the Astera Institute, and support from early proteomics and AI collaborators (Biognosys, Evosep, and Anthropic), the authors of this proposal announce the launch of The Deliverome Project: a coordinated effort to increase the number of actionable targets for precision medicine delivery tenfold within five years.
This project will require collaborators and partners across clinical practice, academia, and industry to join Deliverome Bio, a new Focused Research Organization (FRO), in building, validating, and applying new data for precision delivery. Patient advocacy groups, philanthropic organizations, and government funders will also be needed to champion data collection and rapid, open data release in AI-ready formats, enabling discovery of new targets and development of new therapeutics for precision delivery at unprecedented scale. If this sounds like you, reach out to us at contact@deliverome.org.
Summary
Precision medicine promises to cure not just a disease but your disease by combining custom-built therapeutic payloads with targeted delivery vehicles that hit just the right cells in the body. However, while AI is already accelerating payload development, targeted delivery remains a critical bottleneck.
Targeted delivery is exceptionally difficult. Our bodies have powerful mechanisms to prevent foreign objects from entering our tissues and affecting our genes. Consequently, the field of precision medicine is accumulating an arsenal of anti-disease payloads and delivery vehicles much faster than it can identify effective delivery targets for directing them to the right location. Ultimately, it doesn’t matter how powerful our anti-disease weapons are if they can’t consistently hit their targets and only their targets, especially when any collateral damage to healthy cells can quickly become intolerable.
To solve this, researchers and drug developers need datasets1 that rigorously characterize the deliverome: the set of human cell-surface proteins that could serve as addresses for targeted delivery of precision medicines. The Deliverome Project will produce these datasets by measuring which proteins are specific enough and capable of pulling cargo into cells across human tissues, and releasing the results openly in AI-ready formats.
Motivation
Each year, more than 600,000 Americans die from cancer — more than one a minute. Roughly 1 in 10 Americans (more than 30 million people) has a rare disease, most of which have a genetic origin. Devastating neurodegenerative illnesses without effective treatments continue to proliferate, such that one in three older adults now dies with Alzheimer’s or another form of dementia.
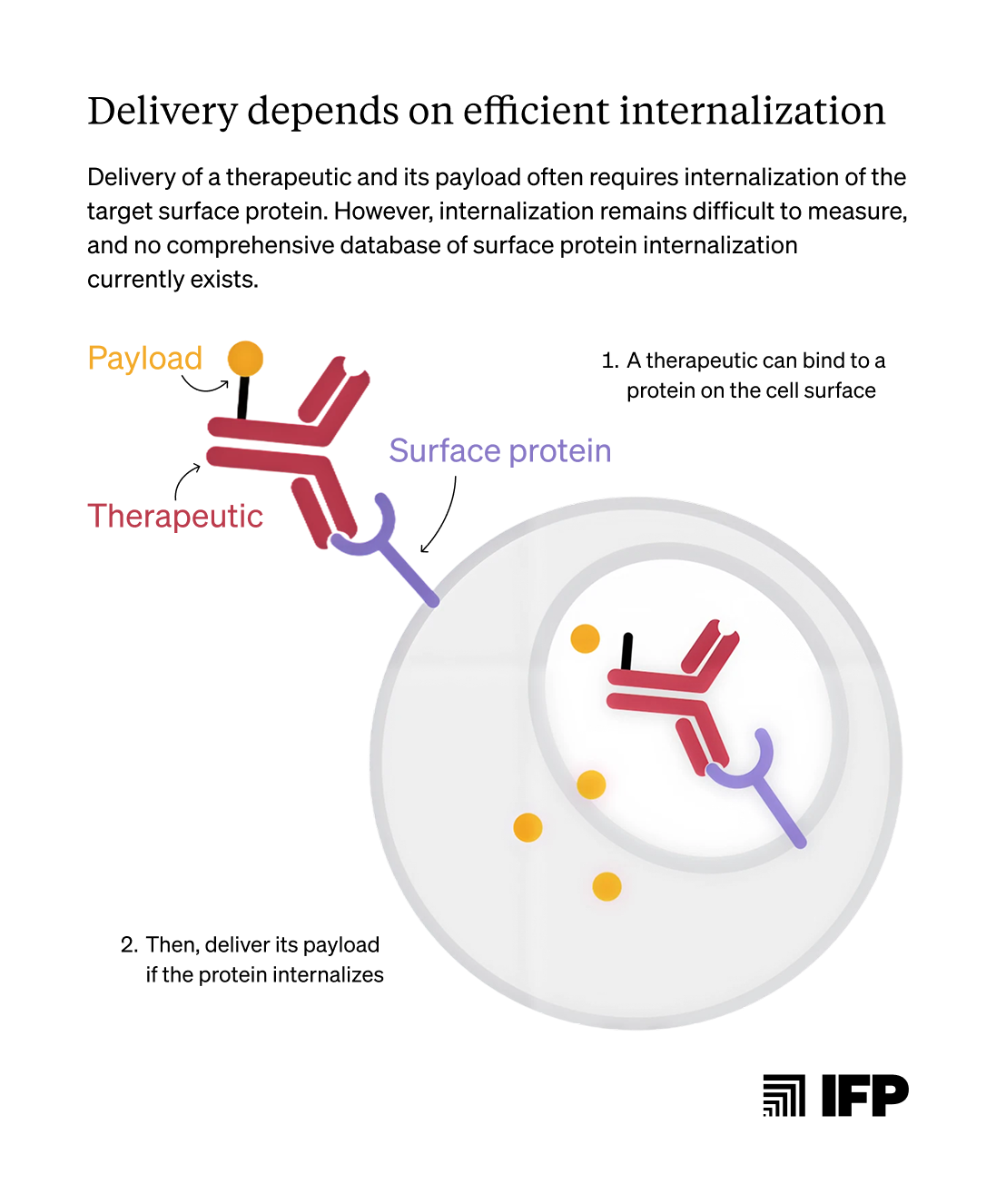
Targeted medicines such as CAR-T cell therapies, antibody-drug conjugates, and CRISPR-based gene editing offer the promise of curing these deadly, costly illnesses. Each targeted medicine is essentially composed of two separate inventions: (a) the payload, which acts once it reaches or enters the target cell — modifying a gene, altering the cell’s activity, or even killing the offending cell outright; and (b) the delivery vehicle, which ferries the medicine (in)to the target cell population while avoiding trillions of bystander cells.
AI is rapidly accelerating the design of both therapeutic payloads and delivery vehicles. AI-first companies such as AI Proteins, Boltz PBC, Chai Discovery, Dyno Therapeutics, Manifold Bio, Nabla Bio, Profluent, and others have become leaders across a range of therapeutic classes. But the effect of these new therapeutics is limited by a bottleneck in our ability to specifically deliver them to cells and tissues of interest outside of the liver.2
When a large-molecule therapeutic (e.g., an antibody or delivery vehicle) is infused into the body, it distributes across many tissues, often accumulating in the liver, which can cause off-target toxic effects and limit efficacy.3 One way to direct medicines to other tissues is by taking advantage of a natural feature of cells called cell-surface proteins. Different cell types express distinct combinations of surface proteins depending on their identity (e.g., kidney versus lung cells), so selecting the appropriate surface protein can help target the correct cells. Cell-surface proteins can also help move a medicine from outside the cell to inside it through a process called internalization.
The history of new therapeutic modalities illustrates the power of finding the right surface protein to target. In the late ’90s, an enormously exciting new modality emerged, offering a way to switch off disease-causing genes. Called RNA interference (RNAi), it won the Nobel Prize in 2006, but did not reach patients until significantly later. For more than a decade, the molecules produced excellent data when applied experimentally in a dish but went nowhere in the body. The payload was decidedly powerful, but researchers had no way to deliver it. The fix, when it finally came, was not a better drug payload, but a better delivery address: scientists discovered a surface protein that sits almost exclusively on liver cells and internalizes its cargo inside within minutes. This is why, to this day, essentially every approved RNAi medicine treats diseases in the liver, where one highly effective address enables a pipeline of medicines for different diseases in the same tissue. Better deliverome data could reveal new addresses, opening the door to delivery across previously inaccessible tissues throughout the body.
The success of RNAi therapeutics shows that delivery requires more than just specificity: the speed at which a surface protein internalizes its cargo is just as critical a determinant of delivery success. The ability to rapidly internalize cargo is so valuable that a fast-internalizing cell-surface protein called the transferrin receptor recently became an FDA-approved delivery target, even though the transferrin receptor’s presence across many tissues can produce off-target effects when it is used as an address. In contrast, highly specific proteins such as CD45 (which mostly exists on immune cells) have seen limited use as delivery targets because they internalize cargo too slowly.
Presently, the field doesn’t know which surface proteins are both specific to a given cell population and capable of efficiently internalizing cargo. The best available databases that map where these surface proteins appear can only give rough estimates and rely on detection reagents (antibodies) that are not fully validated.4 The field also lacks a comprehensive database and even standardized methods for measuring protein internalization. Together, the lack of high-quality deliverome data has left a large, poorly mapped space that is currently explored through slow trial and error, making it expensive and time-consuming to find new delivery targets.
As a result, drug candidates in the therapeutic development pipeline are overwhelmingly clustered around a set of known, reliably targetable surface proteins. For example, more than 80% of antibody-drug conjugates in development target the same 11 surface proteins, representing fewer than 0.5% of the available surfaceome. Thousands of potential individual surface proteins and millions of pairwise surface protein combinations (called a “bispecific” approach) remain unexplored because systematic measurements of their abundance and internalization do not exist to constrain delivery vehicle engineering.
Datasets that suggest new good addresses for drug delivery can be put to use very quickly by researchers. As computational molecular design rapidly improves, once a new target is identified, a novel molecule for the target of interest can be rapidly derisked. Companies such as Beam Therapeutics and Prime Medicine can effectively design new genetic medicines, and in some cases, academic researchers have developed personalized therapies in less than six months. However, many are pursuing the same small set of easy-to-target diseases (e.g., AATD), leaving behind patient communities advocating for genetic cures in disorders such as cystic fibrosis, which has a clear genetic cause but remains hard to specifically target.
The lack of an open deliverome dataset so far is a classic market failure. Current academic and for-profit private research efforts are not incentivized to create broadly useful, large public datasets. For pharmaceutical companies, investigating new surface targets is risky and expensive, requiring years of investment with no guarantee of success. Any actionable insights they generate can later be exploited by competitors that develop slightly better molecules without contributing to the foundational research. Startups face a different constraint: venture capital demands near-term drug candidates and protectable intellectual property, pushing companies to narrow their focus to a single clinical asset rather than maintain broad discovery efforts. Academic researchers, meanwhile, are poorly positioned to fill this gap on their own. Creating comprehensive datasets with sufficient sample size and profiling quality requires a scale of resources and coordination beyond what individual labs can realistically sustain. Additionally, the academic reward system prioritizes novel discoveries published in peer-reviewed journals over the painstaking work of building shared infrastructure. As a result, the field urgently needs a complete deliverome atlas, but no single player in the current system has both the capability and the incentive to create one.
Solution
The targeted delivery problem does not have to plague every single company, and a public good can benefit all innovators in the new medicine space. Accordingly, the Deliverome Project should produce quantitative, tissue- and cell-specific measurements of surface protein abundance and internalization — the missing datasets required to evaluate which surface proteins are suitable as delivery targets.
Critical to both its execution and impact, the Project must serve as an exemplar of open science by releasing protocols, reagents, data, and analytical insights on an ongoing basis. The scale, scope, and potential impact of the project warrant the sustained focus of a dedicated team of scientists, supported by a structure as purpose-built as the data it aims to generate.
Accordingly, the authors of this proposal are launching Deliverome Bio, an independent nonprofit Focused Research Organization (FRO), to coordinate the foundational data generation and platform development efforts of the Deliverome Project. The goal is to build a shared scientific infrastructure that others can extend — enabling laboratories across human disease areas to refine, adapt, and apply the Deliverome framework to specific biological questions and patient populations.
To measure both abundance and specificity, this project will deploy mass spectrometry, which identifies proteins and quantifies their absolute abundance within a sample. In parallel, Deliverome Bio will apply functional genomics approaches to determine which surface proteins support delivery into the cell. Because these methods are inherently high-throughput, they enable systematic interrogation of thousands of surface proteins simultaneously. Recent advances in DNA synthesis technologies and transformative gains in instrument sensitivity now make these measurements possible.
The FRO’s scientific approach will consist of two phases:
- Phase 1 (2 years, $10M, 12 people): while the underlying technologies for making these measurements have progressed, end-to-end validated methods do not yet exist. Deliverome will develop methods for 1) proteomics detection of surface protein abundance, 2) novel proteomics and functional genomics measurements of internalization.
- Phase 2 (3 years, more than $25M, more than 20 people): proteomics measurements of surface protein abundance will be scaled to every healthy tissue and several representative disease areas; functional genomics screening of internalization, routing, and representative cargo delivery will be scaled to dozens of cell lines. Further, the FRO should develop infrastructure to broadly distribute this data through platforms like Open Targets and gather feedback on their use.
Together, these platforms offer a tractable path to the comprehensive data layer for precision delivery across human disease — a public good that can be created once, published openly, and used by everyone.
Call for partners
Generating these datasets will require strong collaborative partnerships for the Deliverome Project, inspired by projects such as the Human Genome Project, to reach its full potential. In particular, the following partnership areas are high priority:
- Healthy human tissue sourcing and metadata: a complete Deliverome will require clinical collaborators, hospitals, and academic researchers to support the proteomics profiling of healthy human tissues and cells from rapid autopsies, discarded donor tissue, and normal adjacent tissue. Samples must be collected and preserved in ways that support downstream analysis, including fresh-frozen preservation for proteomics and high-quality metadata for patient stratification. Progress is currently slowed by long Institutional Review Board and material-transfer timelines, incentives that favor publication credit or licensing revenue over open data sharing, and biobanks that fail to capture or release detailed metadata.
- Biopharma industry partners: Close partnerships will be essential from the start — to identify which data matter most, in which therapeutic areas, and how to fold the results into existing target-prioritization workflows. As these collaborations mature, they will grow into joint validation of priority targets and, ultimately, the translation of those findings into new therapeutics.
- Feedback and scientific collaboration on methods development: a detailed planned scientific approach is available on the Deliverome Project website, and we welcome feedback and collaboration from the proteomics and functional genomics communities. Our current and future partnerships with industry leaders in these fields will enable us to adapt and develop state-of-the-art technologies while navigating the trade-offs between quantitation and scale.
- Contexts that demand higher-resolution biological profiling: Expert input will be needed to determine what additional data are required for a complete Deliverome, whether through finer cell-type resolution or disease-specific profiling. For example, toxicity sinks such as kidney nephrons or liver cell populations may require more granular characterization; complex organ systems like the brain and eye may depend on it; and certain diseases may benefit disproportionately from profiling, whether for patient stratification or surface target discovery.
Beyond this core effort, several expansions of this resource-building effort are possible with additional funding.
- Target validation: minibinder5 or antibody screening campaigns, together with in vivo studies of the engineered molecules, would further derisk high-value delivery targets and facilitate follow-on work by biopharma.
- Tissue proteomic atlases of preclinical animals: to help match the appropriate model to the given target profile and disease indication, reducing the rate of both false-positive and false-negative in vivo results.
- Spatial proteomics: bulk proteomics methods for measuring surface proteins do not capture cell-type heterogeneity or localization, and cellular dissociation can alter the surface proteome. Spatial proteomics methods such as photo-biotinylation and deep visual proteomics can provide additional resolution on cell types and membrane localization in native contexts.
Further resources
- The Human Protein Atlas, 2025. The gold-standard resource for protein expression across human cells and tissues. The Human Protein Atlas integrates multiple protein-level data modalities, including immunohistochemistry (IHC), Olink proteomics, and limited mass spectrometry datasets.
- Ngo, Wu, Wasko, and Doudna. Targeted delivery of genome editors in vivo, 2025. An authoritative review on delivering gene therapies to the right cells in the body to cure diseases.
- Fougner, Cannon, The, Smith, and Leclerc. Herding in the drug development pipeline, 2023. A commentary by McKinsey & Company discussing target crowding in the drug development pipeline, questioning whether pursuing marginal patient benefit to capture market share represents an efficient or impactful use of pharmaceutical R&D spending.
- Chou and Brammer. Rethinking AI for Science Funding, 2026. This blog post makes the case for “blended finance” in AI-for-science: philanthropy and government de-risk foundational open datasets (the AlphaFold/PDB model), venture capital scales validated breakthroughs, and tie capital to real-world milestones rather than valuations.
- Bausch-Fluck, Goldmann, Müller, Oostrum, Müller, Schubert, and Wollscheid. The in silico human surfaceome, 2018. Trained on the experimentally validated Cell Surface Protein Atlas (CSPA) and incorporating a range of protein features, SURFY used machine learning to classify proteins encoded by the human genome as either cell-surface proteins or non-cell-surface proteins.
- Leung, Schaefer, Lin, Yao, and Wells. New approaches and techniques to characterize the human surfaceome, 2025. A recent review of experimental techniques for characterizing surface proteins. In addition to providing an in-depth discussion of methodology, the review also covers aspects of surface protein biology not addressed here, including targetable proteoforms — distinct post-translational features such as protein modifications, conformations, and unique cell-surface complexes.
- von Zastrow and Sorkin. Review of surface protein internalization, 2021. An in-depth review of how cell surface proteins are internalized, signal, and undergo degradation.
-
Research on public datasets like this one have demonstrated that meaningful value is produced through the release of rigorous data. The economist Matteo Tranchero recently found that genome-wide association studies — datasets flagging links between genes and diseases — measurably increased private investment after publication in the targets they surfaced. (Interestingly, about a third of that investment chased false positives, and the firms that avoided these bad investments had the domain knowledge necessary to vet the data. For this reason, a Deliverome dataset that's merely suggestive and unsystematic would invite the same waste in private industry, while one that is rigorous and genuinely quantitative would allow developers to pursue real addresses, something that today's semi-quantitative maps fail to provide.)
-
The need for targeted delivery has been highlighted across therapeutic modalities, including antibody-drug conjugates, blood-brain barrier crossers, gene editing, and lipid nanoparticle delivery vehicles.
-
For example, antibody biodistribution coefficients in preclinical species show brain uptake of less than 0.3%, with the majority of dose accumulating in highly perfused organs like the liver.
-
More than 50% of commercially available antibodies fail at least one independent validation test, contributing to a broader reproducibility crisis in antibody-based research.
-
Minibinders are small, hyperstable de novo–designed proteins that bind a target with high affinity.
