-
- Summary
- Background
- Our current mistake: continuing to export H20 chips
-
Recommendations
- 1. BIS should stop the H20 shipments
- 2. NVIDIA should ensure its compliance with supercomputer end-use restrictions
- 3. BIS should issue a new rule strengthening export controls on inference chips
- 4. The White House should set up a team to monitor and respond to the rapidly changing threat environment
- 5. BIS should track chips after they have been exported
- Technical appendices
Editor’s note (1): Shortly after this piece was published, NVIDIA disclosed that the US government had informed it that the export of H20 chips violates supercomputer end-use restrictions, as we assess in this piece. This means that the first recommendation in this piece (that BIS send NVIDIA an “is-informed” letter) is no longer necessary. We believe implementing Recommendations 3-5 will help ensure the US is better prepared in the future.
Summary
The United States is on the verge of repeating a critical strategic error. Despite having the legal authority and policy tools to constrain China’s access to advanced AI chips, the US government is failing to enforce existing export controls or adapt them to new threats. As a result, Chinese firms are exploiting loopholes to acquire powerful US hardware, undermining America’s lead in frontier AI.
The most immediate risk is the pending export of over 1.3 million NVIDIA H20 chips, worth more than $16 billion, to Chinese tech giants including ByteDance, Alibaba, and Tencent.1 These chips — optimized for AI inference — are likely to be used in Chinese supercomputers, violating US export controls. At least one of the buyers, Tencent, has already installed H20s in a facility used to train a large model, very likely in breach of existing controls restricting the usage of chips in supercomputers exceeding certain thresholds. DeepSeek’s supercomputer used to train their V3 model is also likely in breach of the same restrictions.
This failure is part of a broader pattern:
- Huawei stockpiled restricted chip components, including chip dies and high-bandwidth memory (HBM), before controls took effect.2
- TSMC has facilitated production of over three million cutting-edge chip dies directly for Chinese firms for Chinese AI efforts, sometimes in violation of US rules.3
- DeepSeek, a Chinese lab, trained state-of-the-art models using American chips sold legally due to delayed restrictions.4
The rationale behind export controls remains sound: allowing China to develop frontier AI using cutting-edge chips is an avoidable national security risk. But the administration of export controls is failing to keep pace with new developments in the field. Inference — once seen as secondary — has become central to training, fine-tuning, and increasing the capabilities of deployed models. The H20, a chip specialized in inference, is already 20% faster than the H100 (a currently banned chip) for inference tasks.5
To avoid another preventable failure, the US must act now. We recommend that:
- BIS should immediately block the H20 shipments using its existing authority under 15 CFR § 744.23.
- NVIDIA must investigate and halt transactions that raise legal red flags under its “Know Your Customer” obligations.
- BIS should update export controls to cover inference chips.
- The White House should empower a technical team — ideally within the AI Safety Institute (AISI) at NIST — to forecast AI threats and proactively shape control policy.
- BIS should track chips once exported to high-risk locations by incentivizing industry adoption of chip geolocation features.
The US retains its technological edge — but its advantage is shrinking, and its policy posture is reactive. Without better foresight and enforcement, American technologies will continue fueling China’s ascent in AI.
Background
One of America’s advantages in AI leadership over China is its ability (in collaboration with allies) to produce and control the sophisticated semiconductors necessary to develop AI models, as well as the tools necessary for making them. However, America’s inability to enforce controls fully and update them quickly has led to Chinese companies advancing their capabilities and reducing the size of the US lead.
The rise of Chinese firm DeepSeek caught many American policymakers by surprise, with some calling it a “Sputnik moment” for AI.6 Even more shocking to some was the fact that DeepSeek’s recent R1 and V3 models were largely trained with chips made by NVIDIA, an American company. The vast majority were NVIDIA’s H800 and H20 chips, which we sold freely to Chinese firms.7 H800s (a slightly modified version of NVIDIA’s popular H100 chip) were available on the market for nearly 7 months before the US blocked their sale, and H20s are still available for purchase in China now.8
The US has also struggled to effectively update regulations to control China’s access to key components for chip production. The US government recently learned that Huawei has bought over two million advanced chip dies through shell companies, in direct violation of US export controls. Although a $1 billion fine is being assessed for TSMC, the chip die provider, this lack of oversight has already given Huawei a sizable stockpile of advanced chip components.9 A new regulation — the foundry due diligence rule — was put into effect earlier this year to prevent similar issues in the future. In another case, the plans to impose export controls on high-bandwidth memory (HBM) were leaked nearly 6 months before they were enacted in December 2024, allowing Huawei to stockpile a year’s worth of HBM in advance.10
In each case, earlier intervention could have prevented strategic setbacks to American AI leadership. But despite these oversights, the rationale behind export controls is sound. While NVIDIA’s H20s and H800s are more powerful, they are still less powerful than the H100s and the Blackwell series chips that NVIDIA sells in the US.11 Chinese firms would likely have been able to develop powerful models much more quickly if they had full access to leading American chips. DeepSeek’s CEO put it best: “Money has never been the problem for us; bans on shipments of advanced chips are the problem.”12
The solution to these problems is not to weaken export controls and allow Chinese firms to purchase even more of America’s powerful AI hardware, but rather to forecast and plan better for the future, enact more effective controls, and update them more quickly.
Our current mistake: continuing to export H20 chips
The United States is about to make another strategic mistake: Allowing three Chinese firms to receive over $16 billion in orders for NVIDIA H20 chips, amounting to over 1.3 million chips.13 This order is over six times the size of Colossus, the largest compute cluster in the world.14 It would more than double China’s entire existing stock of H20 chips.15 If these chips are delivered, they will dramatically increase Chinese firms’ ability to develop frontier AI models and deploy them at scale.
NVIDIA’s H20 chips, mostly exempt from US export controls, are powerful GPUs optimized for AI inference.16 Our current controls were put in place at a time when AI inference was not a large part of frontier AI development. But recent breakthroughs have made AI inference — and therefore inference chips — critical to developing frontier models. These chips are used to generate synthetic data to train models, and to conduct newly important training techniques like reinforcement learning. After a frontier model has been trained, inference can now be used to increase model performance while performing tasks. The newest available models, including OpenAI’s o1 and DeepSeek’s R1, can use vast amounts of computational resources to increase the quality of their reasoning.17
Until recently, inference was not critical for frontier AI development. Now, it is, and its importance will likely continue to increase.18 But export controls have not yet caught up to this fact. While the H20 is not particularly fast when used to train AI models, it is 20% faster than the H100 (a banned chip) at inference.19 The H20 is also far more powerful at inference than any chips available for sale in China from non-US companies (see Appendix 1 for more detail).
The Bureau of Industry and Security (BIS) can halt these shipments immediately, but even if it does not, it is likely that these orders are illegal under existing end-use controls.20 These controls are described in 15 CFR § 744.23, paragraph (a)(1), which forbids the export of H20s destined for China if they will be used in a “supercomputer.”21 These H20 chips are likely to be used in computing clusters that violate this restriction. There are two key pieces of evidence that support this conclusion (see Appendix 3 for details):
- The massive size of the order: The $16 billion order corresponds to about 1.3 million H20 chips. To stay under the supercomputer performance thresholds, the Chinese companies would have to build around 500 data centers, each with fewer than ~2,700 H20 chips.22 Because AI data centers benefit massively from centralization and scale, this is unlikely to be the case.
- Evidence of a past breach of the supercomputer rule: At least one of the three buyers, Tencent Holdings, has likely already created supercomputers with H20 chips. According to its own reports, Tencent may have used H20 chips to train its AI model “Hunyuan-Large.”23 While Tencent has not disclosed how long it took to train this model, we calculate that training it while staying under supercomputer thresholds would have taken at least 4 months.24 For comparison, the DeepSeek V3 model was of a similar size, and it was trained in four months, on a cluster that also likely breached the supercomputer end-use rule.25 This makes it likely that Tencent already has a cluster of H20s large enough to qualify as a supercomputer.26
It is theoretically possible that no Chinese company has used the roughly 1 million H20 chips already in the country to build a restricted supercomputer, and that none of the roughly 1.3 million H20 chips of the current order will be used to do so either. But our default expectation should be that Chinese firms are building restricted supercomputers. We discuss this further in Appendices 2 and 3.
Crucially, NVIDIA is supply-constrained, not demand-constrained. Several firms are willing to buy each chip NVIDIA produces.27 NVIDIA’s CEO Jensen Huang has stated that manufacturing capacity is the real constraint,28 and Oracle’s Larry Ellison described a 2024 dinner with Huang and Elon Musk as “begging for GPUs.”29 Halting these orders will reallocate NVIDIA’s (and TSMC’s) production capacity to other buyers: Every chip slot allocated to China’s $16 billion in H20 orders is capacity that could instead be used to manufacture H100s, B200s, or other cutting-edge chips for US buyers and allies. Demand is not dying down: The world’s largest cloud providers — Microsoft, Alphabet, Meta, and Amazon — plan to spend $320 billion on AI infrastructure in 2025, up from $230 billion in 2024.30
Frontier AI models are quickly becoming capable in domains critical to national security.31 Allowing 1.3 million H20s to go to Chinese firms enables them to build dangerous AI capabilities faster, and directly reduces the amount of chips available to US firms. The US government must take action on these orders immediately, and close the gap on inference chips in export controls. More broadly, we must improve our strategic awareness to reduce future gaps in export control design, monitoring, and enforcement, in order to prevent China from developing advanced AI capabilities using American technology.
Recommendations
1. BIS should stop the H20 shipments
BIS should send an “is informed” letter to NVIDIA.32 An “is-informed” letter would immediately stop these planned H20 shipments to ByteDance, Alibaba, and Tencent by informing NVIDIA of their likely violation of supercomputer end-use restrictions described in 15 CFR § 744.23, paragraph (a)(1).33 See Appendix 2 for further details.
Alternatively, BIS could send NVIDIA a “red flag” letter, directing them to investigate the red flags raised by this transaction.34 Although such a letter would not itself halt the transaction, it would give NVIDIA (1) definitive “knowledge” that the red flags exist, thus giving it a duty to investigate the red flags; and (2) “knowledge,” as in “reason to believe,” that the supercomputer end-use restrictions will be violated, which is needed for the supercomputer end-use rule to apply.35.
2. NVIDIA should ensure its compliance with supercomputer end-use restrictions
The size of the H20 orders and evidence of a past breach raise “red flags” as described in The Bureau of Industry and Security’s (BIS) “Know Your Customer” Guidance and Red Flags.36 The same BIS supplement adds that if there are “red flags,” exporters have “a duty” to inquire and not self-blind.37
Orders for almost 500 supercomputers worth of chips for Chinese firms are a red flag that a supercomputer may be built. After the inquiry, the exporter can either:
(A) determine that the red flags can be explained/justified, in which case they may proceed with the transaction; or
(B) determine that they can’t be justified, in which case they must refrain from the transaction or “advise BIS and wait.”
NVIDIA’s inquiry should include an investigation into whether the recipient companies have already violated the supercomputer end-use rule.38 This past compliance information should be supplemented with active oversight mechanisms to monitor whether the supercomputer end-use rule is violated in the future.39
3. BIS should issue a new rule strengthening export controls on inference chips
While an “is informed” letter can address the immediate threat, BIS needs new regulations to control inference chips in the longer term. To close this gap, BIS should issue an interim final rule to amend the Export Administration Regulations.
BIS already controls the export of high-bandwidth memory (HBM) components sold individually, but it does not control chips co-packaged with HBM.40 New controls on such chips are a natural extension of current export controls.
Reports suggest that new regulations covering H20 GPUs may already be ready to be implemented.41 While BIS will be best-placed to determine how inference chips should be controlled, we suggest two possible implementations:
- Restrict the export of any AI chips designed or marketed for use in a data center that are co-packaged (or permanently affixed) with high-bandwidth memory that is otherwise export-controlled as a standalone component.
- Use memory bandwidth as an export-control parameter, adding it to our current parameters of total processing performance and performance density.42
Implementation (A) would allow thresholds and definitions for export control to be reused, simplifying regulations. But it would be less flexible than (B), which would allow thresholds to be set and updated with ease. Ideally, BIS should create controls that can be regularly updated to keep pace with developments in AI technology.
4. The White House should set up a team to monitor and respond to the rapidly changing threat environment
To research scientists and engineers working in the AI industry, it was apparent almost a year ago that inference chips such as the H20 would be crucial for frontier AI development. The US government needs a technically competent team able to provide this kind of situational awareness to policymakers.
Such a team could have helped avoid loopholes in US export controls, warned key US government officials about the growing importance of AI inference compute, and alerted policymakers to the rise of DeepSeek when it became clear to the technical community.
The US AI Safety Institute (AISI) within NIST is the natural home for this capacity. NIST has flexible hiring authorities and high pay scales compared to much of the government, allowing it to more easily hire the competitive technical talent needed. NIST also enjoys the trust of industry and specializes in measurement and evaluation, providing an ideal home for this kind of research. However, NIST’s mission is not focused on national security. The administration, acting through the Secretary of Commerce or National Security Council, should directly task AISI with a clear national security mission, consisting of:
- Making sense of the forthcoming capabilities of American and adversary models and chips based on technical information (such as unreleased model weights, research insights, and foreign chip specifications and manufacturing capabilities).
- Using this information to predict national security implications and producing regular reports on demand for national security decision-makers in the US government.
- Providing expert guidance and recommendations on policy decisions (such as defining the technical parameters used in export controls).
5. BIS should track chips after they have been exported
For more details, see Recommendation 10 in “An Action Plan for American Leadership in AI.43”
Another reason the US has been slow to respond to challenges is that we currently have no effective oversight over where AI chips go after being exported, which has resulted in the development of virtually unchecked AI chip smuggling networks.44 Thankfully, solutions have been developed that could be implemented immediately:45 delay-based location verification46 is an on-chip mechanism that would allow country-level geolocation to detect and deter AI chip smuggling.47 This promising mechanism is both privacy-preserving and resistant to spoofing, and it would not need additional hardware to be incorporated into advanced AI chips.48
Leading US chip firms have not taken the lead on implementing such mechanisms largely because of a lack of incentives to do so. These firms indirectly profit from chip smuggling,49 but the US government has so far not given an unambiguous signal that those incentives will be changed, by exempting chips with geolocation capabilities from further expansions of export controls. There is one exception: BIS included chip location verification capabilities as a requirement to access the National Validated End User (NVEU) authorization, explicitly mentioning delay-based location verification as a possible implementation.50 This kind of conditional access to export markets could be expanded to other areas of the US export control regime. Doing so would create clear incentives for chip firms to implement features that help reduce the risk of smuggling, while also helping chip firms retain their current market access.
BIS should create clear incentives for US chip firms to implement chip geolocation and other on-chip mechanisms that improve oversight and enforcement. One way to do this is through conditional export controls.
In the case of AI chips, this would involve creating a difference in the degree of restrictiveness of export controls, depending on whether chips have security-enhancing mechanisms like chip geolocation. For example: if a chip does not have geolocation capabilities, then it faces higher export restrictions for countries suspected of being smuggling hotspots.51 This would create strong incentives for chip firms to increase on-chip security to access less onerous restrictions, thus giving BIS the ability to use country-level chip location data to detect smuggling and focus its enforcement efforts.
If well-executed, conditional export controls could allow us to have our cake and eat it too: By incentivizing security-enhancing R&D from the private sector, this approach would help US industry maintain export access in allied or neutral countries while better achieving short- and long-term national security objectives. The result would be protections against technology misuse and smuggling that do not compromise American technological competitiveness.
Technical appendices
Appendix 1: Can Chinese companies acquire foreign AI chips that are competitive with H20s?
Not currently. Huawei’s newest chip in the Ascend series, the 910C, would be the most advanced chip sold by a Chinese company.52 It will reportedly have around ~60% of NVIDIA’s H100 performance at AI inference (itself slower than H20 chips).
Even if their performance matched the H20s, Huawei faces serious production capacity issues. Some key components needed to produce Huawei Ascend 910C chips were sourced in violation of US export controls, by purchasing over two million AI chip dies manufactured by the Taiwan Semiconductor Manufacturing Corporation (TSMC) through shell companies. Huawei also stockpiled more than a year’s worth of production of high-bandwidth memory (HBM) components after the announcement of upcoming restrictions on their sale to China. Chinese companies are not currently able to manufacture these advanced components in-house at scale, and a recent foundry due diligence rule should ensure that Huawei can’t source TSMC chip dies through shell companies anymore.53
This means that Huawei may only have enough stockpiles to produce a limited number of Ascend 910C chips (around one million), after which it may be forced to rely on outdated technology before it can catch up.54 Even if stockpiles of components could last several years, production bottlenecks will most likely cause demand by Chinese AI firms to far outstrip Huawei’s supply.
Current BIS regulations provide that “Foreign availability exists when the Secretary determines that an item is comparable in quality to an item subject to US national security export controls, and is available-in-fact to a country, from a non-US source, in sufficient quantities to render the US export control of that item or the denial of a license ineffective” (15 CFR 768.2). The facts above make clear that the criteria of “sufficient quantities” will not be met by the Ascend 910C.
Appendix 2: A short-term solution to prevent H20 exports
The current $16 billion in orders of H20 inference chips by Chinese firms ByteDance, Alibaba Group, and Tencent Holdings are likely in breach of current export controls. BIS has the authority to prevent this, which this technical appendix explains. Longer-term, BIS should strengthen current export controls by controlling AI chips with permanently-affixed (or co-packaged) HBM that is otherwise export-controlled; or it should add total memory bandwidth as an export control parameter.
Authority: BIS can halt large orders of NVIDIA H20 chips through existing end-use controls for supercomputers described in 15 CFR § 744.23, paragraph (a)(1).
This paragraph forbids the export of certain items destined for arms-embargoed countries (those in BIS Country Group D:5), including China, if they will be used in a “supercomputer.”
To use this authority to restrict the sale of H20 GPUs, three things must be true:
- The H20 GPUs are included in the list of items in scope for this regulation.
- The GPUs are destined to a Group D:5 country or Macau.
- The GPUs will be used in a “supercomputer,” as defined in the Export Administration Regulations (EAR).
The rest of Appendix 2 shows that points (1) and (2) above are true, and Appendix 3 provides evidence that point (3) above is likely to be true.
2.1 Evidence
- H20 GPUs are subject to this regulation
§744.23(a)(1)(i) states that the following are items in scope for this regulation:
- An integrated circuit (IC) subject to the EAR and specified in ECCN 3A001, 3A991, 4A994, 5A002, 5A004, or 5A992; or
- A computer, “electronic assembly,” or “component” subject to the EAR and specified in ECCN 4A003, 4A004, 4A994, 5A002, 5A004, or 5A992.
H20 GPUs are included either in the Export Control Classification Number (ECCN) 3A99155 or 4A994 mentioned above.56 4A994 includes computers containing integrated circuits if at least one of these meets or exceeds the limits of ECCN 3A991.p:
ECCN 3A991 includes, among other items:
p. Integrated circuits, n.e.s., having any of the following:
p.1. A processing performance of 8 TOPS or more; or
p.2. An aggregate bidirectional transfer rate over all inputs and outputs of 150 Gbyte/s or more to or from integrated circuits other than volatile memories.
The integrated circuits in H20 GPUs fulfill condition (p)(1), as their processing performance is “296 TFLOPS of INT8, 148 TFLOPS of FP16, 74 TFLOPS of TF32, 44 TFLOPS of FP32.” Although only one condition needs to be met for H20s to be included in ECCN 3A991, they also fulfill condition (p)(2), since they support 4th-generation NVLINK connections of up to 900 GB/s.
- The H20 GPUs are destined to China, which is a D:5 country
§744.23(a)(1)(ii) states that the following destinations and end-uses are in scope:
- The “development,” “production,” operation, installation (including on-site installation), maintenance (checking), repair, overhaul, or refurbishing of a “supercomputer” located in or destined to Macau or a destination specified in Country Group D:5 of supplement no. 1 to part 740 of the EAR; or
- The incorporation into, or the “development” or “production” of any “component” or “equipment” that will be used in a “supercomputer” located in or destined to Macau or a destination specified in Country Group D:5.
The specific $16 billion orders in question were reportedly placed by ByteDance, Alibaba Group, and Tencent Holdings, all of which are headquartered in China (Beijing, Hangzhou, and Shenzhen, respectively). Of course, China is in Country Group D:5, a group of US arms-embargoed countries that corresponds to “Tier 3” in BIS’s Framework for AI Diffusion.
- The GPUs will be used in a “supercomputer,” as defined in the Export Administration Regulations (EAR)
BIS’s definition of “supercomputer” includes both a performance and a volume limitation: a compute cluster within a 41,600 ft³ envelope with performance over 200 (single-precision) petaflop/s is a supercomputer.57
Appendix 3 provides our detailed analysis on why it is likely that the H20 chips in this order will be used in supercomputers.58 In summary, the primary evidence is as follows:
- The massive size of the order: The Chinese companies would have to build over ~500 different clusters with less than ~2,700 H20s each to stay below the 200 PFLOP/s performance limit.
- Evidence that Tencent, one of the three buyers, may have already built a supercomputer with H20 chips. This is based on the 1 million H20 chips already in China, the fact that they indicate they trained their language model Hunyuan-Large on H20 chips, and that doing so while staying under the 200 PFLOP/s limit would have taken them at least 4 months.
- If the buyers follow standard practice in how they arrange their data centers, 200 PFLOP/s clusters made entirely of H20 chips will occupy an estimated volume of ~15,000 ft3 — well within the supercomputer threshold.
[See Appendix 3 for further analysis.]
2.2 Conclusion
The evidence strongly suggests that these latest orders by ByteDance, Alibaba Group, and Tencent Holdings, totaling over $16 billion in NVIDIA H20 GPUs, may violate existing end-use controls on supercomputers in US arms-embargoed countries (of which China is part). Although this evidence raises red flags on its own merits, justifying an inquiry by NVIDIA prior to fulfilling the order (as described in BIS’s “Know Your Customer” Guidance and Red Flags), BIS should preemptively halt the order by delivering NVIDIA an “is informed” letter, as described in the recommendations.
Appendix 3: Evidence that GPUs will be used in a “supercomputer”
“Supercomputer” is defined in 15 CFR 772.1 as follows:
A computing “system” having a collective maximum theoretical compute capacity of 100 or more double-precision (64-bit) petaflops or 200 or more single-precision (32-bit) petaflops within a 41,600 ft3 or smaller envelope.59
Below, we provide analysis and calculations that make clear that it is likely that the recently ordered H20s will be used in supercomputers, as defined by BIS regulations above.
3.1. The GPUs will be used in a cluster exceeding the 200 PFLOP/s threshold
As specified above, the H20 GPUs have a TF32 performance of 74 teraflop/s (TFLOP/s) and FP16 performance of 148 TFLOP/s.
So to reach a supercomputer triggering the end-use rule of 200 or more single-precision (32-bit) petaflop/s (PFLOP/s), one would need ~2,700 H20s (calculation in footnote).60
Reports say that ByteDance, Alibaba, and Tencent have placed “at least $16 billion in orders for Nvidia’s H20 server chips.” At an average price of roughly $12,000 per H20 chip, this amounts to ~1.33 million H20 chips.
There are two reasons to believe that these chips will be used to create a cluster that will exceed ~2,700 H20 chips (200 PFLOP/s), making them “supercomputers” according to the definition above, and thus a generally prohibited end use in China.
Reason 1: The massive size of the orders
1.33 million advanced GPUs is a massive amount. For comparison, the first stage of Project Stargate will see the construction of a data center that will eventually be able to house 400,000 NVIDIA chips. xAI’s Colossus data center in Memphis, Tennessee, recently doubled in size to 200,000 GPUs, keeping the title of “the world’s biggest supercomputer.”
To avoid creating at least one “supercomputer” (of over 200 PFLOP/s), the three Chinese companies would have to create at least 494 clusters of less than 2,700 H20s each (calculations in footnote).61 In the United States, companies rarely build many small compute clusters if they could simply build bigger ones. This is because bigger clusters with highly interconnected chips are more efficient (for example, by enabling large-scale AI model training with minimal efficiency loss). Unless these companies are specifically trying to comply with supercomputer end-use controls, we should expect them to build supercomputers by default.
The size of the order alone should raise “red flags.” According to 15 CFR Supplement No. 3 to Part 732—BIS’s “Know Your Customer” Guidance and Red Flags, two red flags are:
17. The customer is “known” to “develop” or “produce” items for companies located in Macau or a destination specified in Country Group D:5 that are involved with “supercomputers.”
18. The exporter has “knowledge” indicating this customer intends to “develop” or “produce” “supercomputers” or integrated circuits in the future that would otherwise be restricted under § 744.23(a)(1)(i) or (a)(2)(i).
The same supplement adds that “Commerce has developed lists of such red flags that are not all-inclusive but are intended to illustrate the types of circumstances that should cause reasonable suspicion that a transaction will violate the EAR.”
If there are “red flags,” Commerce states that industry has “a duty” to inquire and not self-blind.62 Clearly, orders totalling almost 500 supercomputers for Chinese firms should be a red flag that a supercomputer may be built in violation of the EAR. After the inquiry, the exporter can either (A) determine that the red flags can be explained/justified, in which case they may proceed with the transaction; or (B) determine that they can’t be justified, in which case they must refrain from the transaction or “advise BIS and wait.”
Notably, continuing with the transaction despite not being able to explain or justify the “red flags” puts the exporter at risk of having “knowledge” that would make the transaction a violation of the EAR.63 And “knowledge possessed by an employee of a company can be imputed to a firm so as to make it liable for a violation,” meaning that even employees’ (even if not senior officials) awareness of a high probability that these H20s may be used in supercomputers can make NVIDIA liable for potential EAR violations.64
Reason 2: Past evidence of Chinese companies building supercomputers with H20 chips
Tencent, one of the three buyers in this $16 billion transaction, has most likely created supercomputers with H20 chips already, in violation of the EAR. The evidence is shown below.
If Tencent trained its Hunyuan-Large AI model with H20 GPUs, they would have needed to use less than ~2,700 GPUs to not trigger the supercomputer end-use restrictions. A GitHub repository by Tencent (this is a copy of the original) mentions the use of H20s for training Hunyuan-Large (though note the associated instructions only cover the fine-tuning component of training), which was confirmed by an independent analysis of Hunyuan-Large training procedures.
Tencent’s Hunyuan-Large model has reportedly been trained on 3.5E24 FLOP. Assuming it was trained using H20s, to train such a model on less than ~2,700 GPUs, Tencent would have had to spend between 4 to 9 months (depending on how efficiently they are able to utilize the H20s) training Hunyuan-Large, though the real minimum is probably much closer to 9 months than 4.65 For comparison, the DeepSeek V3 model was about the same size, and it was trained in less than 2 months.66 This makes it likely that Tencent already has a cluster of more than 2,700 H20s, which would be consistent with the vast number of H20s that Chinese companies have already bought to date (NVIDIA has produced at least one million China-specific H20 GPUs in the last year).
3.2. The cluster in which the GPUs are housed will likely stay below the 41,600 ft3 volume threshold for every 200 PFLOP/s, classifying as a “supercomputer”
To count as a supercomputer, the >200 PFLOP/s cluster needs to be in a 41,600 ft3 envelope or less (including empty floor space between racks). The calculations below estimate that a 200 PFLOP/s cluster made entirely of Nvidia H20 chips can comfortably fit within a 41,600 ft3 envelope. This is not meant to be an exact calculation.
- As established above: ~2,703 H100s are ~200 PFLOP/s.
- 2,703 H20s divided by 8 chips per DGX server: 337.875 DGX units (meaning 338 or more DGX servers within the allowable volume would violate the end-use rule)
- Each DGX server (assuming the same DGX server dimensions is used for the H20 as for the H100) measures 14x19x35.3 in., or 9,389.8 in3, or ~5.43 ft3.
- NVIDIA recommends 4 DGX servers per rack.67 Therefore, total racks needed for 2,703 H20s is: 338 / 4 = 84.5 (85 rounded)
- Each recommended rack is 32 x 48 inches of floor space and 84 inches (48U) tall for proper cable management and airflow (although this could be lower).
- 32x48x84 is 129,024 in3, or roughly 75 ft3 of volume per rack.
- 75 ft3 x 85 racks is 6,375 ft3 total volume occupied by the racks, not including floor space.
- Assuming seven-tile aisle pitch (see diagram below) to include floor space, dimensions are:
- Width: 2×4 ft (cold aisles) + 3 ft (hot aisle) + 2×4 ft (two rows of racks times 4ft depth) = 19 ft
- Length: 85 racks / 2 rows * 2.67 ft width per rack ≈ 115 ft
- Height: at least 7 ft (84 inches; 48U) for racks, incl. Airflow.
- Total volume: 19x115x7 ft = 15,295 ft3 (including floor space).
The server rack layout in the calculation above assumes two rows of 43 racks, each with a 3 ft hot aisle between them and 4 ft cold aisles on their back-side. A different configuration could have four rows of ~22 racks each. This would increase the width and decrease the length of the data center, but the volume would remain constant.
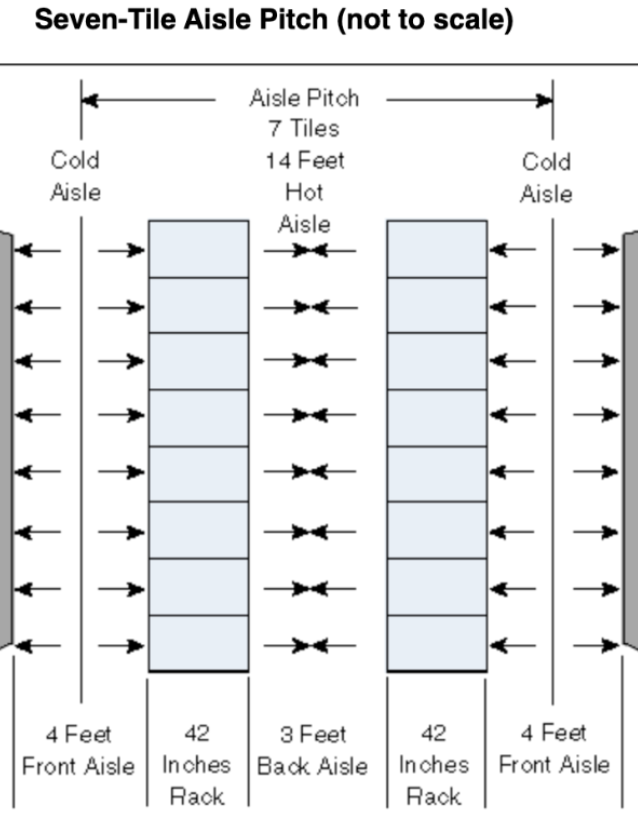
The estimated 15,295 ft3 envelope is significantly less than the 41,600 ft3 threshold, making it likely that a >200 PFLOP/s cluster of H20 GPUs would qualify as a “supercomputer” (and thus be restricted in US arms-embargoed countries) by default.
This calculation should only be taken as a rough estimate. BIS’s definition of “supercomputer” does not specify important details like whether cooling systems should be included in volume calculations, how much floor space is reasonable to include, and more. This estimate shows that a compute cluster full of H20 GPUs exceeding performance limits can comfortably fit within the volume threshold, assuming standard recommended practices.
-
Qianer Liu, “Nvidia Faces Dilemma After Chinese Firms Rush to Order $16 Billion in New AI Chips,” The Information, April 2, 2025.
-
Gregory C. Allen, “DeepSeek, Huawei, Export Controls, and the Future of the US-China AI Race,” Center for Security and International Studies, March 7, 2025.
-
Karen Freifeld, “Exclusive: TSMC could face $1 billion or more fine from US probe, sources say,” Reuters, April 8, 2025.
-
Fanny Potkin and Che Pan, “Nvidia's H20 chip orders jump as Chinese firms adopt DeepSeek's AI models, sources say”, Reuters, February 24, 2025; Mackenzie Hawkins and Jenny Leonard, “Trump Officials Discuss Tighter Curbs on Nvidia China Sales.”
-
H100s are much better for pre-training AI models, but H20 chips are ~20% faster at AI inference; Dylan Patel, Daniel Nishball, and Myron Xie, “Nvidia’s New China AI Chips Circumvent US Restrictions | H20 Faster Than H100 | Huawei Ascend 910B,” SemiAnalysis, November 9, 2023.
-
US House Committee on Science, Space, and Technology, “Research & Technology Subcommittee Hearing - DeepSeek: A Deep Dive,” April 8, 2025.
-
Dylan Patel et al., “DeepSeek Debates: Chinese Leadership On Cost, True Training Cost, Closed Model Margin Impacts,” SemiAnalysis, January 31, 2025.
-
In March 2023, NVIDIA announced the H800 chip for the Chinese market, specifically designed to comply with US export regulations by modifying their flagship H100 chip. On October 23, 2023, the US government notified NVIDIA to immediately halt exports of the H800, implementing recently announced export restrictions.
-
Karen Freifeld, “Exclusive: TSMC Could Face $1 billion Or More Fine From US Probe, Sources Say,” Reuters, April 8, 2025; Gregory C. Allen, “DeepSeek, Huawei, Export Controls.”
-
Mackenzie Hawkins and Ian King, “US Weighs More Limits on China’s Access to Chips Needed for AI,” Bloomberg, June 11, 2024; Bureau of Industry and Security, “Foreign-Produced Direct Product Rule Additions, and Refinements to Controls for Advanced Computing and Semiconductor Manufacturing Items,” 89 Fed. Reg. 96790, December 5, 2024; Gregory C. Allen, “DeepSeek, Huawei, Export Controls.”
-
See Appendix 1 for a comparison of Chinese chips vs. H20s.
-
Jordan Schneider, et. al., “Deepseek: The Quiet Giant Leading China’s AI Race,” ChinaTalk, November 27, 2024.
-
Qianer Liu, “Nvidia Faces Dilemma After Chinese Firms Rush to Order $16 Billion in New AI Chips,” The Information, April 2, 2025.
-
Although Colossus uses H100, not H20 chips. Brian Buntz, “How xAI turned a factory shell into an AI ‘Colossus’ to power Grok 3 and beyond,” R&D World, February 18, 2025.
-
Fanny Potkin and Che Pan, “Exclusive: Nvidia's H20 Chip Orders Jump as Chinese Firms Adopt DeepSeek's AI Models, Sources Say,” Reuters, February 24, 2025.
-
“Inference” refers to running an AI model, rather than training it.
-
François Chollet, “OpenAI o3 Breakthrough High Score on ARC-AGI-PUB,” ARC Prize, December 20, 2024; OpenAI, “Learning to Reason With LLMs,” September 12, 2024.
-
Analysts estimate that by 2026, AI inference will use 4.5 times more compute than AI training (Gregory C. Allen, “DeepSeek, Huawei, Export Controls”; Yan Taw Boon, “The Golden Age of Customized AI Chips,” Neuberger Berman, February 5, 2025). Nvidia CEO Jensen Huang estimated that utilization of its chips for inference (as opposed to AI training) increased from 10% six to seven years ago to 40% in February 2024, before the rise of today’s inference-heavy “reasoning models”; source: Lauren Goode, “Nvidia Hardware Is Eating the World,” Wired, February 23, 2024.
-
H100s are much better for pre-training AI models, but H20 chips are ~20% faster at AI inference; Dylan Patel, Daniel Nishball, and Myron Xie, “Nvidia’s New China AI Chips Circumvent US Restrictions | H20 Faster Than H100 | Huawei Ascend 910B,” SemiAnalysis, November 9, 2023.
-
Despite the fact that H20 chips are not export-controlled alongside more powerful AI chips, such as the Nvidia H100, based on their performance parameters. Instead, the export controls that may be violated are end-use controls.
-
Bureau of Industry and Security, "'Supercomputer,' 'advanced-node integrated circuits,' and semiconductor manufacturing equipment end use controls," 15 CFR § 744.23, last amended March 28, 2025.
-
We also calculate that a standard AI data center housing 2,700 H20 chips will be well below volume limitations (41,600 ft3) to classify as a supercomputer.
-
Ritwik Gupta, “Tencent-Hunyuan-Large,” accessed April 15, 2025, (forked from Tencent, “Tencent-Hunyuan-Large,” GitHub). See also an independent analysis.
-
Depending on model flop utilization (MFU), which we assume may be between 40–90%, as described in Appendix 3.
-
DeepSeek claim to have trained their V3 model in less than 2 months on a cluster of 2,048 H800 chips. DeepSeek-AI, "DeepSeek-V3 Technical Report," February 18, 2025.
-
This would be consistent with the vast number of H20s that Chinese companies have already bought to date (NVIDIA produced at least one million H20 GPUs in 2024; sources: Venkat Somala, “Ban the H20: Competing in the Inference Age,” ChinaTalk, March 7, 2025; Dylan Patel et al., “DeepSeek Debates.”).
-
Gregory C. Allen, “DeepSeek, Huawei, Export Controls.”
-
Daniel Howley and Julie Hyman, “'Demand is just so strong': Nvidia CEO Jensen Huang tells Yahoo Finance supply can't keep up," Yahoo Finance, May 23, 2024.
-
Huileng Tan, “Demand for Nvidia's Chips Is So High that Jensen Huang Had to Assure Analysts the Company is Allocating Them 'fairly,'” Business Insider, February 22, 2024.
-
Louisa Clarence-Smith, “Big US Tech Firms to Spend $300bn on AI Infrastructure,” The Times, February 7, 2025.
-
In late 2023, top models were only able to complete 5% of the cyberattacks tested in the “Cybench” benchmark. In late 2024, they were able to complete a third of them. Across the same period of time, top models began to outperform virology experts in an evaluation designed to test practical virology wet lab skills. Zhang et al., “Cybench: A Framework for Evaluating Cybersecurity Capabilities and Risks of Language Models,” The Thirteenth International Conference on Learning Representations, 2025; Götting, J., et al. “Virology Capabilities Test (VCT): A Multimodal Virology Q&A Benchmark,” arXiv, 2025 (forthcoming); Anthropic, “Progress from our Frontier Red Team,” March 19, 2025.
-
Bureau of Industry and Security, “Guidance to Industry on BIS Actions Identifying Transaction Parties of Diversion Risk,” July 10, 2024.
-
Bureau of Industry and Security, "'Supercomputer,' 'advanced-node integrated circuits,' and semiconductor manufacturing equipment end use controls.”
-
Specifically, numbers 17 and 18; see Bureau of Industry and Security, “‘Know Your Customer’ Guidance and Red Flags.”
-
“Knowledge is defined in the EAR as knowledge of a circumstance (the term may be a variant, such as ‘know,’ ‘reason to know,’ or ‘reason to believe’) includes not only positive knowledge that the circumstance exists or is substantially certain to occur, but also an awareness of a high probability of its existence or future occurrence. When investigating a breach, such awareness is inferred from evidence of the conscious disregard of facts known to a person and is also inferred from a person's willful avoidance of facts. See Part 772 of the EAR.” Source: Bureau of Industry and Security, “Guidance to Industry on BIS Actions.”
-
Specifically, red flags 17 and 18 related to supercomputers (see appendix 3). See: Bureau of Industry and Security, “BIS's ‘Know Your Customer’ Guidance and Red Flags,” 15 CFR Supplement No. 3 to Part 732., last amended March 28, 2025.
-
That is, avoiding information that may reveal rule violations in an attempt to insulate the company from liability; Bureau of Industry and Security, “BIS’s ‘Know Your Customer’ Guidance.”
-
This may be done by shifting the burden of proof to the customers, although it may be hard to verify that this specific rule has not been violated that way. Robust verification may involve carrying out in-person inspections and requesting an accounting of all legally acquired chips, including total performance per cluster (measured in single-precision Petaflops) and the volume in which each cluster’s chips are located. There is precedent for requiring on-site inspections of data centers: Agreeing to on-site inspections is already a requirement for applicants to the National Validated End User (NVEU) authorization, which allows firms in “Tier 2” countries to receive larger quantities of advanced AI chips; see: Bureau of Industry and Security, “Information Required in Requests for VEU Authorization,” Supplement No. 8 to Part 748, accessed April 15, 2025. For “Tier 2” countries, see Lennart Heim, “Understanding the Artificial Intelligence Diffusion Framework,” RAND, January 14, 2025.
-
This may include on-site inspections during data center construction, as well as randomized regular on-site inspections of data centers after construction. Agreeing to on-site inspections is already a requirement for accessing NVEU authorization (see footnote above).
-
That is, chips with “permanently affixed” HBM, meaning that the HBM component cannot be taken out of the chip and used for another chip (e.g., a Chinese-made chip with no built-in performance limitations).
-
Emily Feng and Bobby Allyn, “Trump Administration Backs Off Nvidia's 'H20' Chip Crackdown After Mar-a-Lago Dinner,” NPR, April 9, 2025.
-
This was previously recommended in our response to the Office of Science and Technology Policy’s AI Action Plan Request for Information; see Tim Fist et al., “An Action Plan for American Leadership in AI,” March 17, 2025.
-
Tim Fist et al., “An Action Plan for American Leadership in AI,” Institute for Progress, March 17, 2025. The piece recommends setting conditions for accessing the Low Processing Performance license exception. A forthcoming report on conditional export controls by the Institute for Progress will expand this recommendation to cover other areas of the US export control system; See the LPP license exception at Title 15, Code of Federal Regulations, Part 740, Section 29.
-
Ana Swanson and Claire Fu, “With Smugglers and Front Companies, China Is Skirting American A.I. Bans,” The New York Times, August 4, 2024; Raffaele Huang, “The Underground Network Sneaking Nvidia Chips Into China,” The Wall Street Journal; Qianer Liu, “Nvidia AI Chip Smuggling to China Becomes an Industry,” The Information, August 12, 2024.
-
Tim Fist, Tao Burga, and Vivek Chilukuri, “Technology to Secure the AI Chip Supply Chain: A Working Paper,” Center for a New American Security, December 11, 2024.
-
A report by the Institute for AI Policy and Strategy (IAPS) reads: “Our main finding is that it seems both feasible and relatively cheap to implement pure-software delay-based solutions on chips in the near future. These solutions are likely to aid current AI chip export control enforcement efforts. A solution of this kind would likely cost less than $1,000,000 to set up and maintain for several years.” (Asher Brass and Onni Aarne, “Location Verification for AI Chips,” IAPS, May 6 2024.)
-
Onni Aarne, Tim Fist and Caleb Withers, “Secure, Governable Chips,“ Center for a New American Security, January 8, 2025.
-
It is privacy-preserving because its location data is not precise enough to establish the specific whereabouts of chips, but it is precise enough to determine whether a chip is still in a non-restricted country. It is resistant to spoofing (adversarial tampering to provide incorrect information, see Brass and Arne, “Location Verification for AI Chips”), although adversarial actors may take the chips offline, preventing them from communicating any location information. This would be a red flag in itself, allowing BIS to focus its enforcement efforts on providers, resellers, and end-users whose chips routinely go off the grid. A forthcoming report by the Institute for Progress will provide more information about chip geolocation tamper-resistance.
-
In the sense that, if an AI chip buyer turns out to be a shell company that then ships the chips to a restricted location, the sale will still increase the chip firm’s profits.
-
Bureau of Industry and Security, “Supplement No. 8 to Part 748—Information Required in Requests for VEU Authorization,” 89 Fed. Reg. 80093, October 2, 2024, as amended at 90 FR 4564, January 15, 2025.
-
A tentative list of countries will be included in a forthcoming report on conditional export controls by the Institute for Progress.
-
Still, these raw performance characteristics may overestimate the attractiveness of Huawei’s chips, since a large part of why NVIDIA chips dominate the market is their excellent software for AI applications.
-
While SMIC, a Chinese competitor to TSMC, may also be producing some chip dies for the Ascend 910 series chips, they are struggling to produce at enough scale and with high enough yield.
-
Two Ascend 910B chip dies are needed to produce one Ascend 910C chip. HBM stockpiles could also bottleneck for 910C production, although this is unclear. Finally, around 75% of the Ascend 910Cs are actually functional after the advanced packaging process, which can damage the chips.
-
“Electronic devices, and components, not controlled by 3A001.”
-
4A994 includes computers containing integrated circuits if at least one of these meets or exceeds the limits of ECCN 3A991.p.
-
Petaflop/s (or PFLOP/s) and teraflop/s (TFLOP/s) measures should be assumed to be single-precision (32-bit) for the rest of this document, unless stated otherwise. PFLOP/s denote petaflop per second — a performance metric.
-
This evidence was moved to Appendix 3 to improve readability.
-
The definition also includes the following two notes:
Note 1 to “Supercomputer”: The 41,600 ft3 envelope corresponds, for example, to a 4x4x6.5 ft. rack size and therefore 6,400 ft2 of floor space. The envelope may include empty floor space between racks as well as adjacent floors for multi-floor systems.
Note 2 to “Supercomputer”: Typically, a 'supercomputer' is a high-performance multi-rack system having thousands of closely coupled compute cores connected in parallel with networking technology and having a high peak power capacity requiring cooling elements. They are used for computationally intensive tasks including scientific and engineering work. Supercomputers may include shared memory, distributed memory, or a combination of both. -
1 PFLOP/s = 1,000 TFLOP/s, so 200 PFLOP/s = 200,000 TFLOP/s.
Each H20 GPU provides 74 TFLOP/s (TF32). The minimum number of H20s that will create an aggregate 200,000 TFLOP/s is X, where 74X ≥ 200,000.
X ≥ 200,000/74 ≈ 2,702.7
So 2,703 H20 GPUs will exceed the 200 PFLOP/s “supercomputer” threshold (within certain volume limitations). -
1,333,333 H20 chips ($16 billion / $12,000 per chip) divided by 2,703 H20 chips (maximum before the cluster is considered a supercomputer) ≈ 493.28, rounded up to 494.
-
I.e., “cut off the flow of information that comes to [the exporter firm] in the normal course of business… Do not put on blinders that prevent the learning of relevant information. An affirmative policy of steps to avoid “bad” information would not insulate a company from liability, and it would usually be considered an aggravating factor in an enforcement proceeding” (source: 15 CFR Supplement No. 3 to Part 732).
-
“Knowledge” is defined in the CFR as follows: “Knowledge of a circumstance (the term may be a variant, such as “know,” “reason to know,” or “reason to believe”) includes not only positive knowledge that the circumstance exists or is substantially certain to occur, but also an awareness of a high probability of its existence or future occurrence. Such awareness is inferred from evidence of the conscious disregard of facts known to a person and is also inferred from a person's willful avoidance of facts.”
-
This constitutes “knowledge” — see definition above.
-
This calculation is based on model FLOP utilizations (MFUs) between 90% (for 67 days) and 40% (for 151 days). See calculations in Google Colab.
-
Although the official DeepSeek report says “less than two months.”
-
Although this number could be lower in practice.
